
RNN Voice Cloning: Neural Network Guide
RNN voice cloning uses Recurrent Neural Networks to create realistic, human-like synthetic voices by learning tone, rhythm, and emotional nuances from voice samples. Compared to older text-to-speech (TTS) systems, it produces more natural and personalized results. Here's a quick breakdown:
-
Key Features:
- Captures unique voice traits like tone and rhythm.
- Maintains context for coherent speech using memory states.
-
Core Components:
- Voice Embeddings: Digital "fingerprints" of a voice.
- LSTM Units: Handle long-term memory for natural flow.
- Vocoder Systems: Convert neural outputs to audio.
-
Applications:
- Personalized voices for speech disabilities.
- Realistic virtual assistants and voiceovers.
Quick Comparison
| Feature | Traditional TTS | RNN Voice Cloning |
|---|---|---|
| Voice Quality | Robotic | Natural and human-like |
| Personalization | Limited | Highly tailored |
| Emotional Expression | Basic | Captures nuances |
| Context Handling | Basic | Advanced with memory |
RNN voice cloning is transforming TTS systems with better personalization, emotional expression, and context adaptation. However, challenges like high data requirements, computational demands, and ethical concerns remain. Future advancements like combining RNNs with transformers and improving data efficiency aim to make this technology more accessible and responsible.
Voice Cloning Made Simple: Learn to Use Tacotron2 for TTS Voice Models
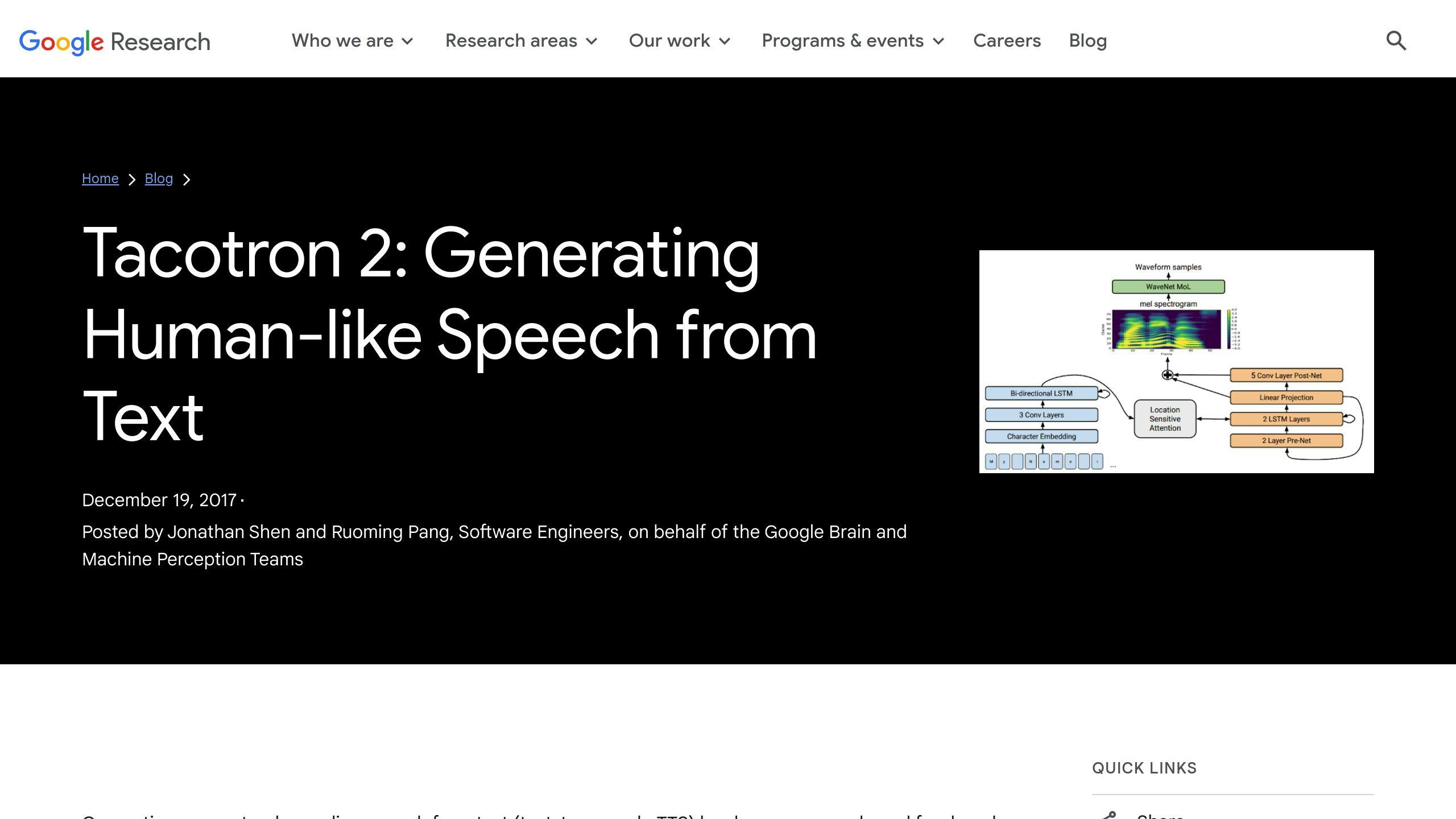
How RNN-Based Voice Cloning Works
RNN-based voice cloning uses advanced deep learning techniques combined with audio processing to create synthetic voices that sound natural and closely mimic human speech patterns. The key lies in the ability of RNNs to handle sequential data effectively.
Training and Core Components
The process starts with gathering high-quality audio recordings from the target speaker. These recordings go through preprocessing steps like noise reduction and normalization to ensure uniformity. RNNs then analyze this data, identifying and replicating the speaker's unique vocal traits, including rhythm, tone, timbre, and even emotional nuances.
Several key components work together to make this possible:
- Voice Embeddings: These compact data representations capture the unique characteristics of a speaker's voice, serving as a digital "fingerprint."
- LSTM Units: These units help the system maintain long-term memory, enabling it to generate speech that is coherent and contextually appropriate.
- Vocoder System: A vocoder transforms the neural network's outputs into audio waveforms. Systems like HiFi-GAN are often used to improve the quality of the synthesized voice.
Common Challenges in the Process
Despite its capabilities, voice cloning with RNNs comes with a set of challenges. Researchers and developers work to address these issues through innovative solutions:
| Challenge | Solution Approach |
|---|---|
| Limited Training Data | Using data augmentation methods |
| Voice Consistency | Fine-tuning with more samples |
| Computational Efficiency | Designing optimized architectures |
Uses and Benefits of RNN Voice Cloning
Applications in TTS Systems
RNN voice cloning has become a game-changer in several industries, especially in advanced text-to-speech (TTS) systems. One standout use is creating personalized voices for individuals with speech disabilities. Instead of relying on generic synthetic voices, this technology helps maintain their unique vocal identity, offering a more natural way to communicate.
Virtual assistants are another prominent area where RNN voice cloning shines. It creates consistent, natural-sounding voices, improving user interactions. Industries like customer service and education benefit greatly from this, as it enhances engagement and ensures a seamless experience.
In the entertainment and media world, RNN voice cloning is used for realistic voiceovers. From dubbing to localizing content, it adds authenticity and depth to productions.
Benefits Compared to Other TTS Methods
RNN voice cloning stands out when compared to traditional TTS systems. Here's a quick breakdown:
| Feature | Traditional TTS | RNN Voice Cloning |
|---|---|---|
| Voice Personalization | Limited to preset voices | Customizable with personal voice traits |
| Emotional Expression | Basic or robotic | Captures natural emotional nuances |
| Speech Pattern Accuracy | Generic patterns | Learns and mirrors individual speech |
| Context Adaptation | Fixed responses | Adapts to various contexts seamlessly |
RNN-based systems excel at mimicking subtle changes in tone, pitch, and rhythm, allowing them to convey emotions effectively. This makes the speech feel more natural and engaging, ideal for accessibility tools and communication aids. The result? More intuitive and smoother interactions that sound closer to real human voices.
sbb-itb-c2c0e80
Challenges and Future Directions for RNN Voice Cloning
Key Challenges in RNN Voice Cloning
RNN voice cloning faces several hurdles that limit its broader use. One of the main issues is dataset diversity. Models require varied, high-quality voice samples to accurately capture speech nuances. This becomes especially problematic for underrepresented accents and languages, where such datasets are scarce.
Another challenge is the computational demands of the technology. Running these models often requires significant resources, which can be a barrier for smaller organizations or individual developers. Here's a breakdown of the main technical challenges:
| Challenge | Impact | Current Mitigation Strategies |
|---|---|---|
| Dataset Requirements | Struggles with diverse voice accuracy | Use of transfer learning techniques |
| Computational Power | High infrastructure costs | Leveraging cloud-based computing |
| Model Complexity | Longer training times | Adoption of one-shot learning methods |
Ethical concerns are also a pressing issue. The risk of creating unauthorized voice replicas raises serious privacy and security questions. This has led to calls for stricter regulations and the incorporation of consent mechanisms in voice cloning tools. Addressing these concerns is critical to ensuring the responsible use of this technology.
Although these challenges are significant, advancements in the field are continuously driving improvements in efficiency, accessibility, and ethical safeguards.
Future Developments in RNN Voice Cloning
The future of RNN voice cloning is shaped by exciting technological progress. For example, combining transformers with RNNs is producing more natural voice outputs by merging RNNs' sequential strengths with transformers' ability to understand larger contexts.
Techniques like transfer learning, which adapts pre-trained models to new tasks with minimal data, and multi-speaker modeling are helping to reduce the data requirements for training. This makes voice cloning more resource-efficient and easier to implement.
Emerging innovations like diffusion probabilistic modeling (which refines noisy signals into clear audio) and HiFi-GAN models are further improving the quality and speed of voice cloning systems.
To tackle ethical challenges, tools like digital watermarking and AI-based detection systems are being developed. Digital watermarking embeds unique markers in cloned voices, while detection systems work to identify unauthorized synthetic speech. Advanced consent mechanisms are also being explored to ensure proper use of the technology.
These advancements are setting the stage for RNN voice cloning systems that are efficient, responsible, and easier to use.
Conclusion
Key Takeaways
RNN voice cloning showcases impressive progress in replicating realistic speech. These networks are particularly effective at modeling long-term speech patterns, making them a core component of modern text-to-speech (TTS) systems. Use cases range from accessibility tools to content creation, with techniques like transfer learning reducing the need for large datasets. However, ethical concerns - such as ensuring consent and protecting security - remain critical as the technology advances.
| Aspect | Current State | Future Direction |
|---|---|---|
| Voice Quality | Natural and human-like | Improved emotional expression |
| Data Requirements | Large datasets needed | Moving toward one-shot learning |
| Implementation | Complex infrastructure | Simplified cloud-based solutions |
| Ethical Framework | Developing standards | Advanced consent mechanisms |
Access to the right tools and resources will be key to successfully using this technology.
Useful Resources for TTS Solutions
If you're looking to explore RNN voice cloning, having the right tools is essential. The Text to Speech List is a helpful resource, offering a directory of TTS tools and services. It allows you to compare options from leading cloud providers and AI platforms. Staying informed about advancements also means diving into technical documentation and practical guides, as cloud-based solutions become increasingly user-friendly.
When choosing a TTS solution, focus on factors like model accuracy, resource efficiency, dataset quality, ethical compliance, and how well it integrates with your needs.
FAQs
What is the main advantage of LSTM over RNN?
Long Short-Term Memory (LSTM) networks have a clear edge over traditional Recurrent Neural Networks (RNNs) when it comes to voice cloning. The standout feature of LSTMs is their advanced memory system, which works somewhat like a computer's memory.
Here’s how LSTM's memory capabilities improve voice cloning:
| Feature | LSTM Advantage | Impact on Voice Cloning |
|---|---|---|
| Memory Duration | Retains long-term information | Maintains speaking style and patterns over time |
| Information Control | Can read, write, and delete data | Allows precise tuning of voice characteristics |
| Sequential Processing | Handles long-term dependencies well | Ensures consistency in longer speech segments |
LSTMs excel at capturing subtle elements of human speech, such as:
- Tonal patterns: Ensures a consistent voice tone in lengthy sequences.
- Speaking rhythm: Keeps natural pauses and timing intact.
- Emotional context: Preserves emotional nuances throughout speech.
This makes LSTM-based voice cloning more dependable, especially for longer speech tasks where maintaining a consistent voice is crucial. By remembering and applying learned speech patterns, LSTMs deliver more natural and realistic voice synthesis compared to traditional RNNs.